
最近我在思考这样一个问题,顺便看一下gpt对这个问题的解释。搜索发现:
团队写代码,为什么要遵循coding guideline?
-
一致性:编码准则确保整个团队的代码风格和格式是一致的,这使得团队成员之间更易于交流和协作。这也使得代码更容易维护和更新,因为其他人可以更轻松地理解代码。
-
可读性:编码准则有助于提高代码的可读性。通过对代码进行格式化和注释,代码会更易于阅读和理解,从而减少错误和缺陷,并提高代码的质量。
-
可维护性:编码准则有助于提高代码的可维护性。通过使用一致的格式和风格,团队成员可以更轻松地理解代码,并进行更快速的故障排除和修复。
-
代码质量:编码准则有助于提高代码的质量。通过要求团队成员编写可读性高、可维护性强的代码,编码准则可以确保代码更加健壮、可靠和安全。这也有助于减少代码缺陷和错误,提高代码的可靠性和可用性。
-
代码重用:编码准则有助于提高代码的重用性。通过编写符合标准的代码,团队成员可以更容易地将代码重用在其他项目中,从而提高生产力和效率。
继续搜索:
对于一个使用bash为主要语言的项目,业界推荐的coding guideline?
-
使用有意义的变量名:变量名应该具有描述性,以便其他人可以轻松地理解代码。
-
缩进:使用4个空格作为缩进,而不是制表符。
-
注释:对代码进行注释,以解释代码的目的和功能。注释应该清晰、简洁,并且易于阅读。
-
函数:编写短小精悍的函数,每个函数都应该具有一个特定的目的。函数应该使用有意义的名称,并且应该清晰地描述其目的和功能。
-
错误处理:在代码中包含错误处理,以确保代码在遇到错误时不会崩溃或产生不可预测的结果。
-
使用双引号:在引用变量时,使用双引号而不是单引号,以确保变量扩展能够正常工作。
-
使用全局变量:尽量避免使用��全局变量,因为它们很难调试和维护。
-
使用命令替换:使用
$()语法而不是反引号``来执行命令替换。 -
使用数组:使用数组来管理相关变量,而不是使用多个单独的变量。
-
使用“
set -u”:使用“set -u”来检查未定义的变量,以避免在引用未定义的变量时产生错误。
这些规范有助于提高 Bash 代码的可读性、可维护性和可靠性。
然后我搜索 "bash script style guideline",最上面的结果是:
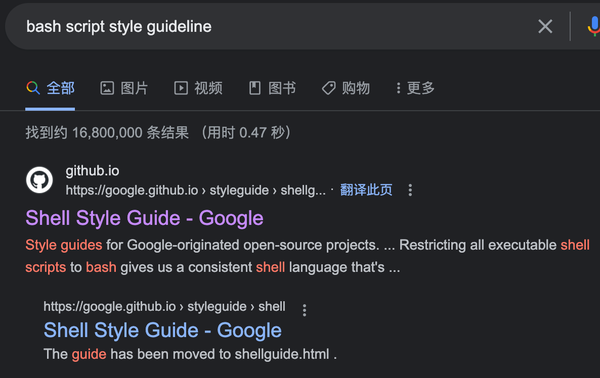
即:代码规范:https://google.github.io/styleguide/shellguide.html
我仔细阅读了这份风格指南,对其中的“局部变量”的章节很感兴趣。
文中说:「最好把局部变量的定义与赋值,换行实现,不要写到同一行上」,以免掩盖报错状态码。
Declare function-specific variables with
local. Declaration and assignment should be on different lines.Ensure that local variables are only seen inside a function and its children by using
localwhen declaring them. This avoids polluting the global name space and inadvertently setting variables that may have significance outside the function.Declaration and assignment must be separate statements when the assignment value is provided by a command substitution; as the
localbuiltin does not propagate the exit code from the command substitution.
我动手验证这个细节,发现��果然如此:
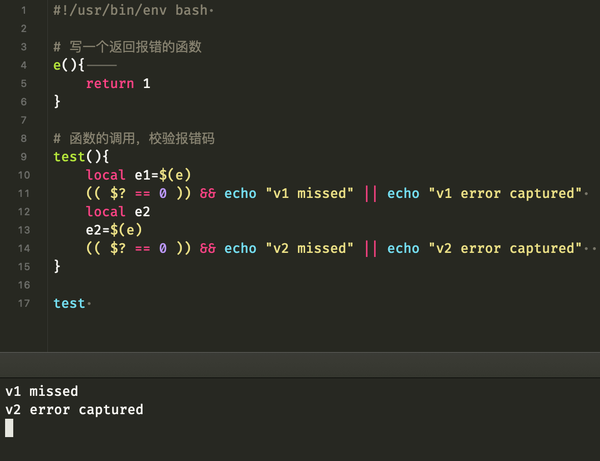
然后我开始自查当前的项目,寻找类似于如下风格的代码:
local my_var="$(my_func)"
优化后的预期结果:
local my_var
my_var="$(my_func)"
在 https://regex101.com/ 测试代码的运行。给出范例
regex:
local fn=$(echo $name_ver| tr ':' '-').tar.xz
test string
local fn=$(echo $name_ver| tr ':' '-').tar.xz #普通
local fn=$(echo $name_ver| tr ':' '-').tar.xz # 模拟多个空格
local fn=$(echo $name_ver| tr ':' '-').tar.xz # 模拟tab缩进
local fn="$(echo $name_ver| tr ':' '-').tar.xz" # 模拟带引号的变量声明
测似乎生成的代码
$1local $2\n$1$2=$3
生成的代码
$re = '/^(\s*)local\s+(\w+)=("?\$\(.*)/m';
$str = ' local fn=$(echo $name_ver| tr \':\' \'-\').tar.xzt
local fn=$(echo $name_ver| tr \':\' \'-\').tar.xzt
local fn=$(echo $name_ver| tr \':\' \'-\').tar.xz
local fn="$(echo $name_ver| tr \':\' \'-\').tar.xz"';
$subst = "$1local $2\n$1$2=$3";
$result = preg_replace($re, $subst, $str);
echo "The result of the substitution is ".$result;
精简为 perl_oneliner:
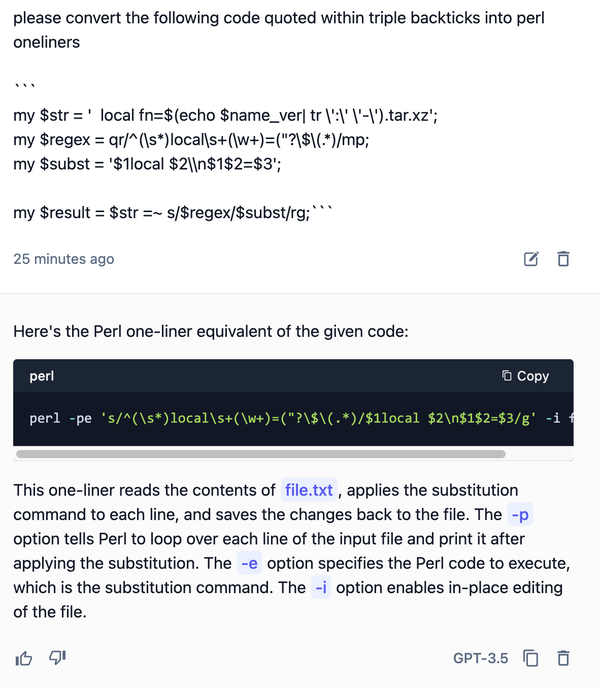
perl -pe 's/^(\s*)local\s+(\w+)=("?\$\(.*)/$1local $2\n$1$2=$3/g' -i file.txt
测试的场景:
搜索代码
pcregrep -lr '^(\s*)local\s+(\w+)=("?\$\(.*)' *
批量修正:
perl -pi -e 's#^(\s*)local\s+(\w+)=("?\$\(.*)#$1local $2\n$1$2=$3#' $(pcregrep -l -r '^(\s*)local\s+(\w+)=("?\$\(.*)' * )
修正之后,仔细阅读diff,检验效果,发现符合预期。
后续:增加git hook检测代码
为了让以后新增的代码,也都符合上述规范,我增加了这样一个 pre-commit脚本。这样,每次提交之前,它都会帮我确保代码合规。
同时,我在编辑器里,设置了shfmt、shellcheck之类的规范,并设置为format on save,即,保存时自动格式化,来自动处理格式问题。
# test code
if ! grep -wq 'Code violates rules' .git/hooks/pre-commit; then
cat >> .git/hooks/pre-commit <<'GIT_PRE_COMMIT_EOF'
#!/usr/bin/env bash
if find . -name '*.sh'| xargs pcregrep '^\s+local\s+\w+="?(`|\$\()'; then
echo "Error: Code violates rules"
echo 'use: local var'
echo 'var="$(...")'
echo 'instead of local var=``'
echo 'or local var="$(...)"'
echo 'as of explained in https://google.github.io/styleguide/shellguide.html'
exit 1
fi
GIT_PRE_COMMIT_EOF
chmod +x .git/hooks/pre-commit
fi
总结:
- 寻找业界规范
- 遵循规范
- 修改过去不合规范的代码
- 新增��代码确保合规
- 将代码的规范检查,加入到日常的流程里。(goimport check)
- 越早做,历史包袱越少。越晚做,历史包袱越沉重。